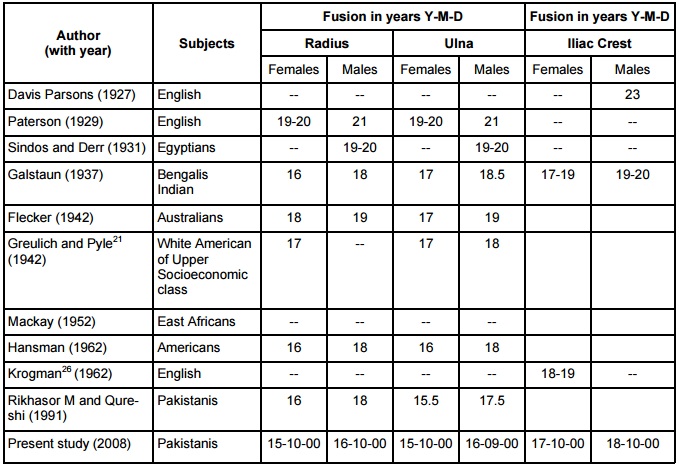
Det finns egentligen bara två personer jag tycker är lika mig. Den ene är min bror och han är, well, väldigt lik mig. Fast kortare och mer välvårdad. Den andra är Isobel. Älskade Iso. Eftersom hon inte alls ser ut som mig (men har samma organisatoriska förmåga, I assure you) så ska jag visa en bild på 'na:

Nu tänker ni kanske "Men det där är ju en framstående opinionsbildares bylinebild!" (vilket är sant) eller "Jaha så Per vill bara påminna oss om att hans vänner är granna" (också sant), men se så ligger det inte till för nu ska vi prata om igenkänning och vad det innebär och för att liksom lura in er i det så lovar jag att skriva lite om Isobels nuna. Jag är begåvad på det viset. Men först ett par ord om bildigenkänning.
Datorer har varit fruktansvärt dåliga på att känna igen vad en bild föreställer, även om de håller på att bli dramatiskt mycket bättre. Att förstå att en bild på en häst är en bild på en häst är trivialt för de flesta människor, men vad som skiljer hästpixlar från t.ex. hundpixlar kan vara rätt knivigt för ett datorprogram. Och då har vi inte kommit in på problemet med att skilja hästpixlar från ryttarpixlarna som kanske befinner sig i samma bild. Är det fortfarande en bild av en häst eller av ett ekipage eller vad?
Eftersom apparater med hjärnor ("folk") är så mycket bättre på att känna igen bilder än apparater utan hjärnor (folks datorer) så är det lockande att försöka datorer klassificera bilder som hjärnor gör. Detta är ett artificiellt neuralt nätverk (ANN) och den enkla versionen lyder som följer: Ett program får simulera ett antal låtsasneuron, som är ordnade i två eller flera lager i ett elegant tomrum som vi kan tänka på som en väldigt stiliserad hjärna om vi vill. Och det vill vi. Sedan matar man den i stort sett helt orealistiska hjärnan med en massa bilder på t.ex. hästar och låter den veta att det enda bilderna har gemensamt är att de föreställer just hästar. Lista ut vari hästigheten ligger! Chop chop!
Det är nu det börjar bli intressant. Hittepåneuronen ligger som sagt travade i lager, som en tårta. Det första lagret, själva tårtbottnen, är det som matas med den ursprungliga bilden. Det sista lagret - vispgrädden - är det som producerar hittepåhjärnans output, t.ex. svaret på frågan om en bild föreställer en häst eller inte. Det finns många sätt att göra en gräddtårta, men det genomgående temat är att ju högre upp man kommer genom de olika lagren, desto mer komplicerade särdrag identifieras i bilden. Långt ner trålas efter egenskaper som t.ex. huruvida ett fält är mörkt eller ljust, om en kontur är ett hörn eller en linje, osv. Längre upp mot jordgubbarna kan neuronen försöka reda ut om en viss uppsättning ränder är en fjäder eller en hästman.
Det de olika lagren gör är att de letar efter en statistisk egenskap med det otympliga svenska namnet framträdandeaktighet eller det betydligt elegantare engelska saliency. Jag har skrivit om detta i ett annat sammanhang förrut, men här menas att en samling pixlar blir mer framträdandeaktiga ju lägre sannolikheten är att de skulle ha ordnat sig på ett visst sätt. Några pixlar kan råka bilda en linje av ren slump då och då, men att många pixlar ska råka bilda en väldigt lång och regelbunden linje är väldigt osannolikt. Att extremt många pixlar ska råka ordna sig till en bild av Ina Scott som vinner Prix d'Amerique är alldeles fenomenalt osannolikt och därmed alldeles fenomenalt framträdandeaktigt.
Alla föreställande bilder innehåller massvis av alldeles enastående osannolika särdrag, men visar man det neurala nätverket tillräckligt många bilder på hästar så börjar det fatta vilka särdrag som är hästlika. Detta fungerar förvånansvärt bra. Här har man matat ett ANN tränat för att känna igen hundar med en bild (den övre bilden) och låtit den producera en ny bild där de pixlar den tycker är väldigt hundaktiga är ljusa och ovidkommande pixlar är mörka:

Sådana här program klarar av att sätta rätt etikett på bilder ungefär lika ofta som människor, i alla fall om man begränsar sig till enklare motiv. En lite konstig sak, däremot, är hur fruktansvärt säkra på sin sak de här nätverken är när de helt uppenbart har katastrofalt fel:

I det vänstra fallet klarar programmet av att med 99.99% säkerhet säga att en bild på en gitarr föreställer en gitarr och en på en pingvin föreställer en pingvin. Gott så. Men i det högra fallet så matar man samma program med ett par nonsensbilder som det med lika stor säkerhet kallar för gitarr respektive pingvin. Det finns två uppenbara tolkningar av detta, som inte nödvändigtvis är ömsesidigt uteslutande: 1) Datorsimuleringar är fortfarande riktigt korkade, och 2) Kanske blir människor lika lurade som datorsimuleringar ibland.
Jaja, hur som helst. En gång för vad som känns som väldigt länge sedan så åt jag i alla fall middag med Isobel. Detta var i samband med en akutplacering jag hade gjort som läkarkandidat (det var med andra ord inte så länge sedan, egentligen) där en Tråkig Och Ointressant Patient Som Kandidaten Kan Ta Hand Om Själv plötsligt började bete sig konstigt och ha framträdandeaktigt olikstora pupiller. Vad som orsakade detta ska vi inte gå in på här, men det slutade inte bättre än att den nu inte alls tråkiga patienten skickades urakut till neurokirurgen och kandidaten gick och drack kaffe väldigt mycket snabbare än vad som är socialt påbjudet. Vid middagen ett par dagar senare påpekade därför den nu lugnare kandidaten att Isobels pupiller faktiskt också är olika stora, men att detta verkar vara permanent och knappast tillräckliga skäl att ringa NK-jouren. De andra närvarande vid middagen försökte sitt allra bästa att se skillnaden i pupillstorlek själva, men verkade inte så övertygade. Ett klassiskt fall av att tidigare erfarenheter primat en att se något som kanske eller kanske inte finns där, även känt som att alla problem ser ut som spikar om allt man har är en hammare. Även om jag står fast vid att jag hade rätt och David bara inte tittade tillräckligt noga. Ni kan ju titta på bilden själv om ni inte tror mig. De är olika stora.
Det är inget att skämmas för, det händer den bäste. Även de bästa neurala nätverken, faktiskt. En grupp forskare i Oxford tränade en massa nätverk att känna igen olika saker, som citroner, rävar och tvättmaskiner. Sedan matade man dem med bilder på rent brus (det vi vanliga dödliga kallar myrornas krig när det dyker upp på teve) och lät nätverken förstärka de särdrag som av ren slump liknade en citron eller räv eller vad det nu var det allra minsta lilla. Och sedan börja om. Det som liknade en citron aldrig så lite i början blev mer och mer citronlikt för varje ny vända och till slut fick man rätt igenkännbara citroner. När livet inte gav det neurala nätverket citroner så blev det i alla fall lemonad till slut:

Många känner nog igen det här från bilderna från det neurala nätverket Deep Dream som fyllt medierna med rubriker om att "datorer drömmer" och dylikt de senaste veckorna. Eftersom man numer kan ladda upp sina egna bilder till Deep Dream så ville jag veta vad den tyckte om Isobels ögon. Den... var inte till någon hjälp:

Hon har hundar i sitt hår som bara ett neuralt nätverk på en googleserver kan se! Aja, ibland ser man saker som inte finns där, men tiotusenkronorsfrågan är ju egentligen: Om nu en datorsimulering klarar av att göra samma saker rätt som en människa samt dessutom begår samma misstag, kan det vara så att simuleringen och människan gör samma sak?
Glad att ni frågade!
I en brand spanking new artikel i Nature Neuroscience resonerar ett par forskare vid UCSD så här: Alla sensoriska kretsar i hjärnbarken är ordnade som en väldigt specifik slags gräddtårta. I lager 2 och 3 finns excitatoriska neuron som tar emot "obehandlad" sensorisk information från lager 4, liknande de bilder man matar de artificiella neurala nätverken med. Lager 2/3 tar också emot input från lager 1, vilket är ett senare steg, ett lager av tårtan som så att säga ligger närmare jordgubbarna. Är det möjligt att lura ett djur att "se" saker som inte finns genom att träna cellerna i lager 1, utan att påverka cellerna i lager 4?
Genom att låta möss springa på ett rullband medan man skapade en synvilla som lurade musen att den sprang snett så tränade man upp en grupp celler i en del av hjärnan som heter retrospleniala kärnan (ingen fara, jag har inte heller hört talas om den). Dessa har den lite lustiga egenheten att de skickar information vidare till lager 1 men inte lager 4 i den del av syncortex som kallas V1, vilket hade effekten att L4-cellerna minskade sin aktivitet som svar på synvillan medan L1-cellerna ökade sin aktivitet för den. Trots detta fortsatte L2/3-cellerna i V1 att reagera adekvat på synvillan. Detta tolkar de som att V1 primats att tolka vissa synintryck som just den synvillan, att de så att säga satt en hammare i handen på någon i en värld full av spikar. (Hemläxa: Ta en titt på den artikeln och förklara vad den har att säga om den vit- och guldfärgade klänningen.)
Det här ger en del stöd åt att Deep Dream kanske fungerar som en riktig hjärna på ett grundläggande sätt. Utöver att neurala nätverk går hjälpligt som en anka och kvackar lika illa som en anka så verkar det som om de behandlar information på samma sätt som ankors nervceller gör.
Dessutom har David fel.
Det de olika lagren gör är att de letar efter en statistisk egenskap med det otympliga svenska namnet framträdandeaktighet eller det betydligt elegantare engelska saliency. Jag har skrivit om detta i ett annat sammanhang förrut, men här menas att en samling pixlar blir mer framträdandeaktiga ju lägre sannolikheten är att de skulle ha ordnat sig på ett visst sätt. Några pixlar kan råka bilda en linje av ren slump då och då, men att många pixlar ska råka bilda en väldigt lång och regelbunden linje är väldigt osannolikt. Att extremt många pixlar ska råka ordna sig till en bild av Ina Scott som vinner Prix d'Amerique är alldeles fenomenalt osannolikt och därmed alldeles fenomenalt framträdandeaktigt.
Alla föreställande bilder innehåller massvis av alldeles enastående osannolika särdrag, men visar man det neurala nätverket tillräckligt många bilder på hästar så börjar det fatta vilka särdrag som är hästlika. Detta fungerar förvånansvärt bra. Här har man matat ett ANN tränat för att känna igen hundar med en bild (den övre bilden) och låtit den producera en ny bild där de pixlar den tycker är väldigt hundaktiga är ljusa och ovidkommande pixlar är mörka:

Sådana här program klarar av att sätta rätt etikett på bilder ungefär lika ofta som människor, i alla fall om man begränsar sig till enklare motiv. En lite konstig sak, däremot, är hur fruktansvärt säkra på sin sak de här nätverken är när de helt uppenbart har katastrofalt fel:

I det vänstra fallet klarar programmet av att med 99.99% säkerhet säga att en bild på en gitarr föreställer en gitarr och en på en pingvin föreställer en pingvin. Gott så. Men i det högra fallet så matar man samma program med ett par nonsensbilder som det med lika stor säkerhet kallar för gitarr respektive pingvin. Det finns två uppenbara tolkningar av detta, som inte nödvändigtvis är ömsesidigt uteslutande: 1) Datorsimuleringar är fortfarande riktigt korkade, och 2) Kanske blir människor lika lurade som datorsimuleringar ibland.
Jaja, hur som helst. En gång för vad som känns som väldigt länge sedan så åt jag i alla fall middag med Isobel. Detta var i samband med en akutplacering jag hade gjort som läkarkandidat (det var med andra ord inte så länge sedan, egentligen) där en Tråkig Och Ointressant Patient Som Kandidaten Kan Ta Hand Om Själv plötsligt började bete sig konstigt och ha framträdandeaktigt olikstora pupiller. Vad som orsakade detta ska vi inte gå in på här, men det slutade inte bättre än att den nu inte alls tråkiga patienten skickades urakut till neurokirurgen och kandidaten gick och drack kaffe väldigt mycket snabbare än vad som är socialt påbjudet. Vid middagen ett par dagar senare påpekade därför den nu lugnare kandidaten att Isobels pupiller faktiskt också är olika stora, men att detta verkar vara permanent och knappast tillräckliga skäl att ringa NK-jouren. De andra närvarande vid middagen försökte sitt allra bästa att se skillnaden i pupillstorlek själva, men verkade inte så övertygade. Ett klassiskt fall av att tidigare erfarenheter primat en att se något som kanske eller kanske inte finns där, även känt som att alla problem ser ut som spikar om allt man har är en hammare. Även om jag står fast vid att jag hade rätt och David bara inte tittade tillräckligt noga. Ni kan ju titta på bilden själv om ni inte tror mig. De är olika stora.
Det är inget att skämmas för, det händer den bäste. Även de bästa neurala nätverken, faktiskt. En grupp forskare i Oxford tränade en massa nätverk att känna igen olika saker, som citroner, rävar och tvättmaskiner. Sedan matade man dem med bilder på rent brus (det vi vanliga dödliga kallar myrornas krig när det dyker upp på teve) och lät nätverken förstärka de särdrag som av ren slump liknade en citron eller räv eller vad det nu var det allra minsta lilla. Och sedan börja om. Det som liknade en citron aldrig så lite i början blev mer och mer citronlikt för varje ny vända och till slut fick man rätt igenkännbara citroner. När livet inte gav det neurala nätverket citroner så blev det i alla fall lemonad till slut:

Många känner nog igen det här från bilderna från det neurala nätverket Deep Dream som fyllt medierna med rubriker om att "datorer drömmer" och dylikt de senaste veckorna. Eftersom man numer kan ladda upp sina egna bilder till Deep Dream så ville jag veta vad den tyckte om Isobels ögon. Den... var inte till någon hjälp:

Hon har hundar i sitt hår som bara ett neuralt nätverk på en googleserver kan se! Aja, ibland ser man saker som inte finns där, men tiotusenkronorsfrågan är ju egentligen: Om nu en datorsimulering klarar av att göra samma saker rätt som en människa samt dessutom begår samma misstag, kan det vara så att simuleringen och människan gör samma sak?
Glad att ni frågade!
I en brand spanking new artikel i Nature Neuroscience resonerar ett par forskare vid UCSD så här: Alla sensoriska kretsar i hjärnbarken är ordnade som en väldigt specifik slags gräddtårta. I lager 2 och 3 finns excitatoriska neuron som tar emot "obehandlad" sensorisk information från lager 4, liknande de bilder man matar de artificiella neurala nätverken med. Lager 2/3 tar också emot input från lager 1, vilket är ett senare steg, ett lager av tårtan som så att säga ligger närmare jordgubbarna. Är det möjligt att lura ett djur att "se" saker som inte finns genom att träna cellerna i lager 1, utan att påverka cellerna i lager 4?
Genom att låta möss springa på ett rullband medan man skapade en synvilla som lurade musen att den sprang snett så tränade man upp en grupp celler i en del av hjärnan som heter retrospleniala kärnan (ingen fara, jag har inte heller hört talas om den). Dessa har den lite lustiga egenheten att de skickar information vidare till lager 1 men inte lager 4 i den del av syncortex som kallas V1, vilket hade effekten att L4-cellerna minskade sin aktivitet som svar på synvillan medan L1-cellerna ökade sin aktivitet för den. Trots detta fortsatte L2/3-cellerna i V1 att reagera adekvat på synvillan. Detta tolkar de som att V1 primats att tolka vissa synintryck som just den synvillan, att de så att säga satt en hammare i handen på någon i en värld full av spikar. (Hemläxa: Ta en titt på den artikeln och förklara vad den har att säga om den vit- och guldfärgade klänningen.)
Det här ger en del stöd åt att Deep Dream kanske fungerar som en riktig hjärna på ett grundläggande sätt. Utöver att neurala nätverk går hjälpligt som en anka och kvackar lika illa som en anka så verkar det som om de behandlar information på samma sätt som ankors nervceller gör.
Dessutom har David fel.